
How much League of Legends data is enough data?

League of Legends is a game of change. Adapting to patches has been a challenge for professionals since the game was launched. Champions, items, and strategies get weaker or stronger every couple of weeks. If a team wants to get an edge over the competition, it is essential for them to find out what works in the current meta. Ideally, they would want to find that out before the meta even exists.

At Bayes Esports, we are facing the same issues as professional players. When we create betting odds, we apply machine learning to predict which side is going to win or get an objective. The probabilities we produce depend on what our models believe is strong or weak.
The more recent the data is, the better the current meta is reflected in our algorithms. In a perfect world we would want to train our models just on yesterday’s data. But unfortunately it takes way more matches than are played in one day in League of Legends.

It’s tempting then to instead use data from the last five years. This, unfortunately, does not work either. Factors like champion strength can change with each patch or whenever a counter pick is discovered. What is needed are models that understand that the game is constantly evolving while also being resistant to sudden changes.
So how relevant is the data from two years ago? Where is the sweet spot between getting enough matches and maintaining relevant data for our models to work best? We conducted a small research project with some exciting results.
Our experimental setup was very straightforward. Since League of Legends patches last roughly two weeks, we divided our dataset into two-week slices. We then repeatedly trained a model that we would normally use to create map winner odds, giving it data from more and more patches. The results were always tested on the most recent matches, which were not part of the training set. We repeated this experiment with different starting times, equating “now” for example with January 2022.
If the game two years ago is very similar to what it looks like now, we would expect the overall accuracy to increase as we keep adding data. If patches completely change the game, then we would expect there to be a sharp cut off in prediction accuracy. It is important to do similar research on different periods, because the changes in the game are not consistent.
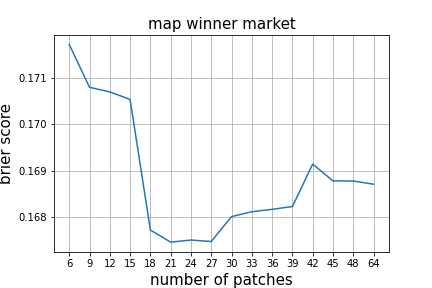
In order to evaluate model performance, we used a Brier score. This is a metric to measure prediction accuracy. Roughly speaking, the lower the Brier score, the more accurate the model. Comparing Brier scores we consider a difference of at least 0.005 to be significant.

Our research shows that a model predicting map winners trained on 5,000 games from 21 patches (~10.5 months) is the most accurate. We also clearly see that the size of the dataset from only the most recent 12 patches is too small. It is important to point out that the differences in accuracy are mostly minor, but they are statistically significant. It’s precisely these tiny differences that may win or lose you a bet against a clever punter who has studied the current meta.
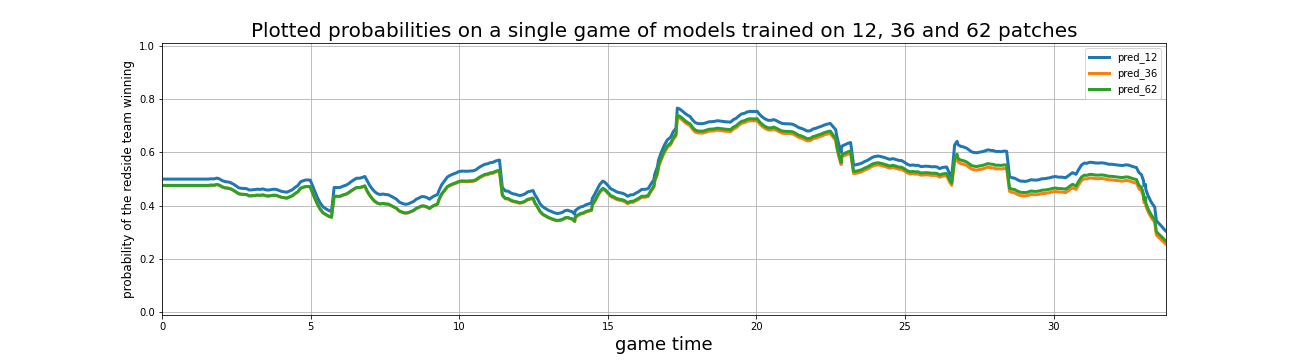
What’s also important to look at is how models trained on different amounts of matches behave. One interesting insight is that different patches will favour different sides. In the plot below, the model trained on the most recent 12 patches is favouring the red side more than the ones trained on 36 or 62, as we see probabilities starting not quite at 0.5 – the case where both teams are equally likely to win.
This, too, makes sense if we think that one side in LoL does have an inherent advantage, and this side can very well change between patches.
Ultimately our research has shown that the optimal timeframe will always be between 6 and 12 months worth of patches and around 3,000 games will be the minimum sample required in order to obtain the best predictions.
Intuitively, this makes a lot of sense. The game might change abruptly with a patch, but it takes time for the player population to adjust and develop a new meta. And not all patches will be equally significant for the competitive scene either.
With the unique data we have it is important to get the most out of it. The game evolves. If Bayes Esports wants to keep its position at the forefront of the esports betting industry, we have to make sure to stay connected and be aware of the changes to produce the most accurate models and odds.